蚂蚁EGSS算法破解Test Time Scaling困局 | ACL 2026
蚂蚁EGSS算法破解Test Time Scaling困局 | ACL 2026更聪明的计算远比更多的计算更有效。
来自主题: AI技术研报
6618 点击 2026-06-17 14:06
 搜索
搜索
更聪明的计算远比更多的计算更有效。

近年来,大语言模型(LLMs)在复杂推理任务上的能力突飞猛进,这在很大程度上得益于深度思考的策略,即通过增加测试时(test-time)的计算量,让模型生成更长的思维链(Chain-of-Thought)。
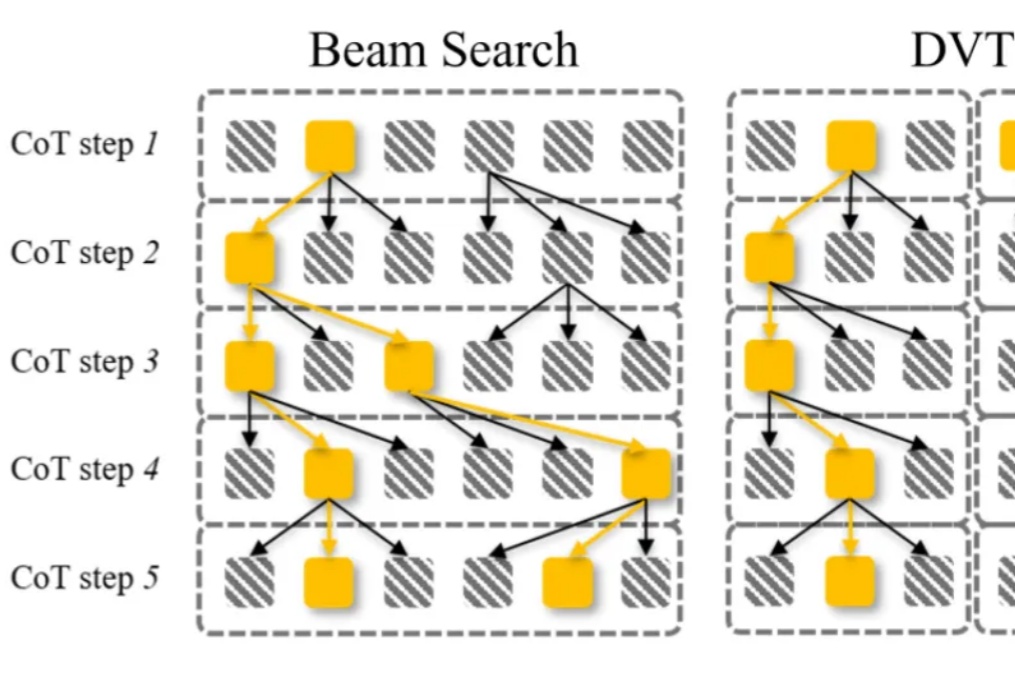
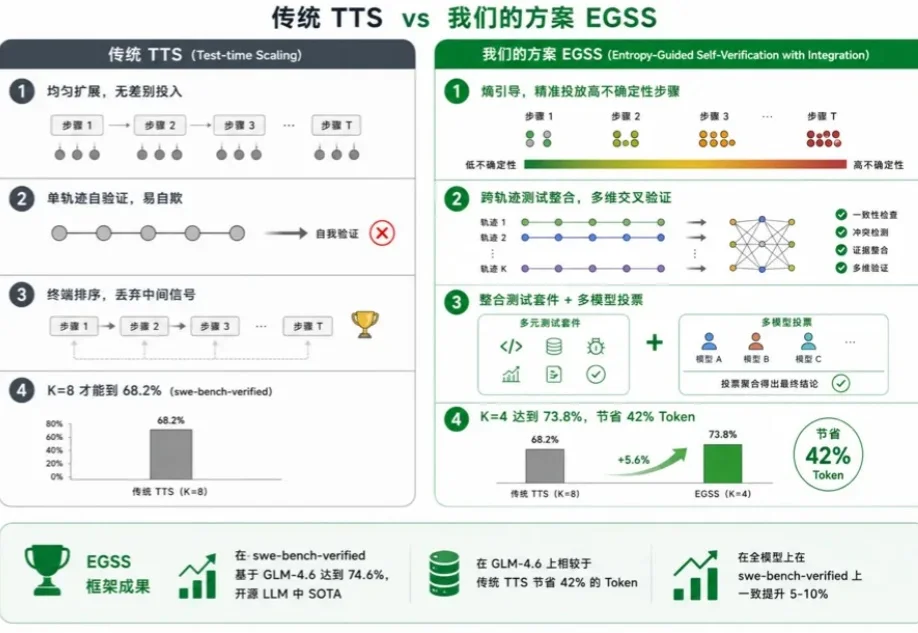
大语言模型通过 CoT 已具备强大的数学推理能力,而 Beam Search、DVTS 等测试时扩展(Test-Time Scaling, TTS)方法可通过分配额外计算资源进一步提升准确性。然而,现有方法存在两大关键缺陷:路径同质化(推理路径趋同)和中间结果利用不足(大量高质量推理分支被丢弃)。
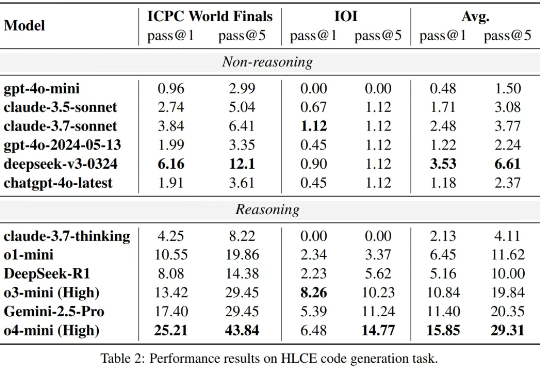
大语言模型(LLM)在标准编程基准测试(如 HumanEval,Livecodebench)上已经接近 “毕业”,但这是否意味着它们已经掌握了人类顶尖水平的复杂推理和编程能力?
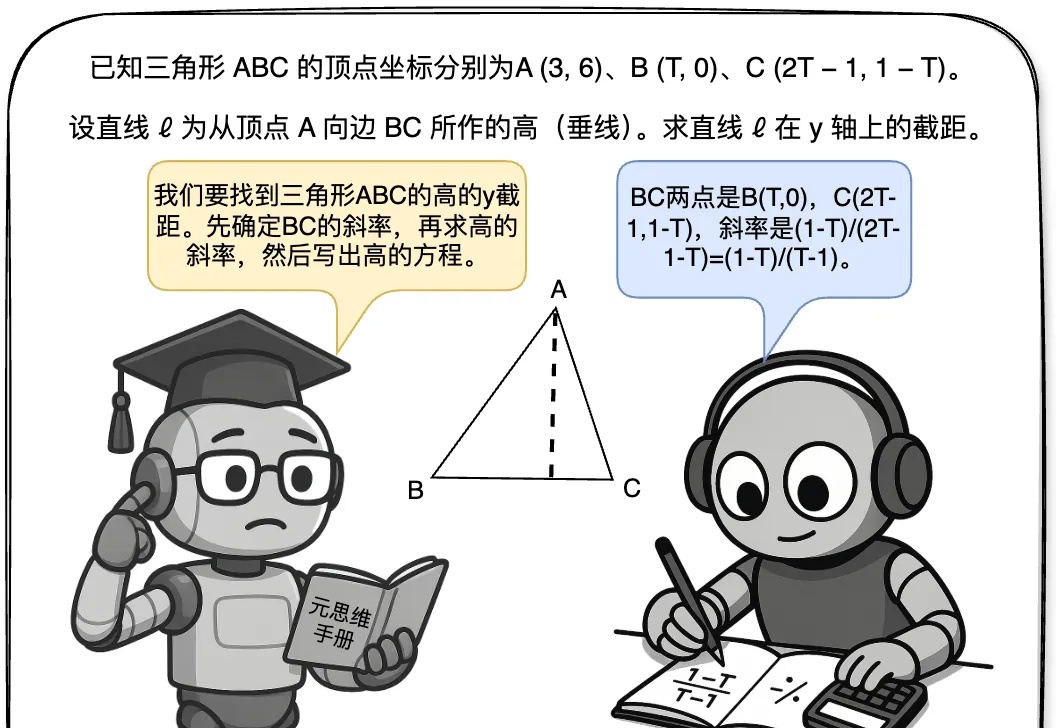
最近,关于大模型推理的测试时间扩展(Test time scaling law )的探索不断涌现出新的范式,包括① 结构化搜索结(如 MCTS),② 过程奖励模型(Process Reward Model )+ PPO,③ 可验证奖励 (Verifiable Reward)+ GRPO(DeepSeek R1)。
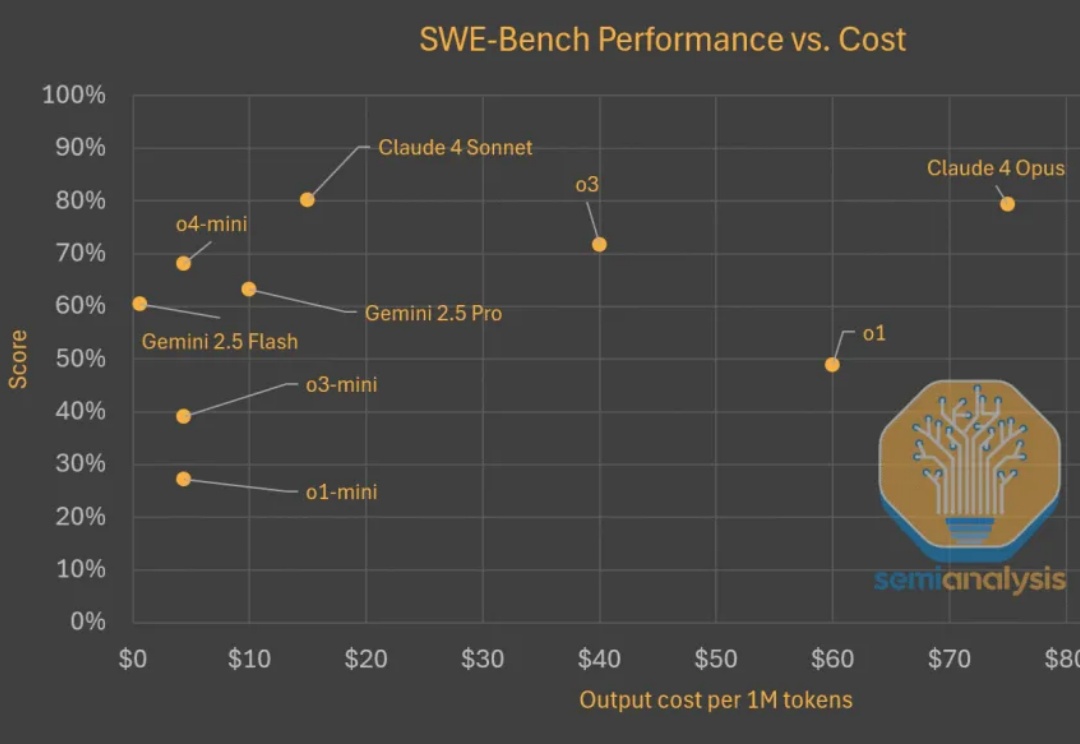
Test time scaling范式蓬勃发展。推理模型持续快速改进,变得更为高效且价格更为亲民。在评估现实世界软件工程任务(如 SWE-Bench)时,模型以更低的成本取得了更高的分数。以下是显示模型变得更便宜且更优秀的图表。